
Have you ever wondered how ChatGPT, Gemini, Claude, or Copilot can write formal emails, explain code, or summarize complex paragraphs so effortlessly? Whether you’re a techie or not, it’s hard to ignore how everyone today relies on these AI tools. At the heart of most of these systems lies a powerful architecture called Transformers.
But what exactly are Transformers?
Why do we need them?
And how do they work behind the scenes?
Let’s unravel the mystery.
The Struggle with Older Models
Before Transformers, we had models like RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory). These models processed text one word at a time, which made them slow and inefficient for understanding long or complex sentences.
Imagine reading a paragraph but forgetting the first sentence by the time you reach the end — that’s exactly what happened with RNNs. They had trouble holding onto context, which is a huge problem for tasks like:
- Language Translation
- Text Generation
- Sentiment Analysis
Clearly, we needed something better: a model that could look at the entire input at once and understand deeper relationships between words.
The Game-Changer: Transformers
In 2017, Google researchers introduced the Transformer architecture in their groundbreaking paper “Attention Is All You Need.”
Unlike RNNs, Transformers process the entire sentence simultaneously, which makes them faster and far more effective at understanding context. The core idea that powers this magic? A mechanism called Self-Attention.
Demystifying Self-Attention
Let’s make this simple with an example:
“The animal didn’t cross the road because it was too tired.”
When you read the word “it,” your brain automatically links it to “The animal.” That’s context — understanding how words relate to each other in a sentence.
Self-Attention does the same thing:
It helps the model figure out which words should focus on which. It allows the model to assign weights (or importance) to each word in relation to the others.
So instead of reading left to right blindly, the model looks at the entire sentence and asks:
“Which words are important to each other?”
Now imagine multiple such attention mechanisms running in parallel — one focusing on word relationships, another on grammar, another on meaning. This is called Multi-Head Attention, and it lets the model learn different aspects of language simultaneously.
Anatomy of a Transformer Encoder Block
So what’s inside a Transformer block? Let’s break down the core components with a helpful diagram:
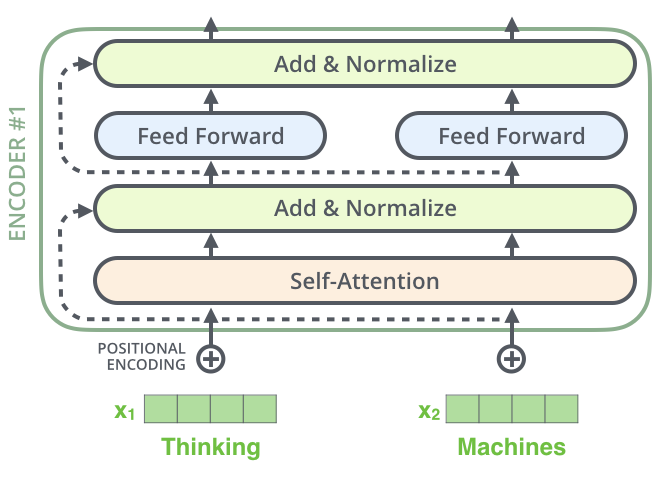
1. Input Embedding + Positional Encoding
Each word is converted into a numerical vector (embedding). Since Transformers don’t read in order, positional encoding is added to indicate word position in the sentence.
2. Self-Attention
This layer allows the model to compare every word with every other word and determine relationships. It’s the brain of the Transformer.
3. Add & Normalize
The self-attention output is added back to the input (a technique called residual connection) and then normalized. This helps stabilize training.
4. Feed-Forward Network (FFN)
A small neural network further processes the information, helping the model transform and refine the word vectors.
5. Add & Normalize (Again!)
Another round of residual connection and normalization — keeping the model steady, even as it stacks multiple layers.
Why Transformers Matter
Transformers are not just another model — they are the foundation of modern AI language tools. From generating emails to translating languages and writing poetry, these models understand language contextually, flexibly, and scalably.
By introducing the concept of Self-Attention, Transformers changed the game — allowing machines to understand language more like humans do.
Next time you ask ChatGPT to rewrite your email or explain a bug in your code, remember — behind the scenes, a Transformer is hard at work, connecting the dots, one attention layer at a time.
Stay tuned for Part 2
We’ll break down how Transformers generate responses, decode meanings, and scale across billions of parameters. You don’t want to miss it!Let’s Connect!
Have questions or thoughts? Reach out to me on LinkedIn — I’d love to hear from you.
