
Picture this: it’s 7:45 AM! The trading desk is humming, markets are opening in minutes, and somewhere deep in a maze of Excel files, a formula has quietly broken overnight.
Nobody knows yet. The rule-based engine that calculates risk exposure is still running, but it’s running on yesterday’s logic. A portfolio manager frantically scrolls through tabs, cross-referencing macros, trying to pinpoint which cell triggered the cascade. The phone rings. A trade is on hold. Every minute costs money.

This wasn’t a rare occurrence. It was Tuesday.
The Machine That Couldn’t See Tomorrow
Portfolio managers had built their entire operational workflow inside Excel, from daily risk calculations to trade checks to anomaly detection. These spreadsheets were clever, but they were fundamentally static. They could not watch, learn, adapt, or self-correct.
The Day We Stopped Patching and Started Listening
We needed something that could actively watch the system, understand issues the moment they surfaced, and take coordinated action, without relying on fragile, static rules or waiting for a human to notice.
Imagining a Better Way — What If AI Could Think Like a Team?
Imagine you could hire a team of expert assistants, each laser-focused on one job, but capable of passing their findings seamlessly to the next person in line. One assistant monitors error logs 24/7 and never gets tired. Another evaluates every possible fix and scores them by risk. A third actually writes the code change. A fourth runs the tests to make sure nothing breaks.
Now imagine they work in milliseconds, not hours — and they learn from every incident they handle.
That’s not a fantasy. That’s CrewAI.
What is AgenticAI (CrewAI)
CrewAI is an open-source framework for orchestrating multiple AI agents that collaborate to complete complex, multi-step tasks. Each agent is assigned a specific role, given the right tools, and can pass context to the next agent — like a well-coordinated human team, but operating at machine speed.
Why CrewAI Won the Evaluation
let’s understand why CrewAI stands out-
Autonomous Operation: Agents make smart decisions based on their assigned roles and available tools
Natural Collaboration: Agents communicate and work together like human teammates
Easy to Extend: Adding new capabilities, tools, and roles is straightforward
Production-Ready: Built for real-world applications, not just experimentsCost-Efficient: Optimized to reduce API calls and token usage
Building the Dream Team
Great teams aren’t built around job titles. They’re built around roles that matter — the one who sees the problem before anyone else, the one who weighs the options without flinching, the one who gets their hands dirty and makes the change, and the one who won’t let anything ship until it’s right.
In software, we rarely have all four in the same room at the same time. With CrewAI, we built them. Meet the crew that now runs quietly in the background of Product’s trading infrastructure — four agents, four distinct personalities, one shared purpose: keep the system alive and the trades flowing.
The system implements a sophisticated multi-agent pipeline with state management, inter-agent communication, and fault-tolerant execution. The workflow operates through four primary phases with built-in checkpoints and rollback mechanisms:
What this workflow achieves –
This workflow replaces brittle, manual spreadsheets with an autonomous Agentic AI framework that proactively detects and fixes system errors. By orchestrating specialized agents to analyze tracebacks, implement solutions, and validate fixes against live tests, it eliminates the need for human intervention in correlating logs and tuning rules, ensuring a scalable and self-healing trading environment.
Workflow divided in 4 phases:
- Analysis Phase
- Evaluation Phase
- Implementation Phase
- Testing Phase
Let’s understand them one by one…
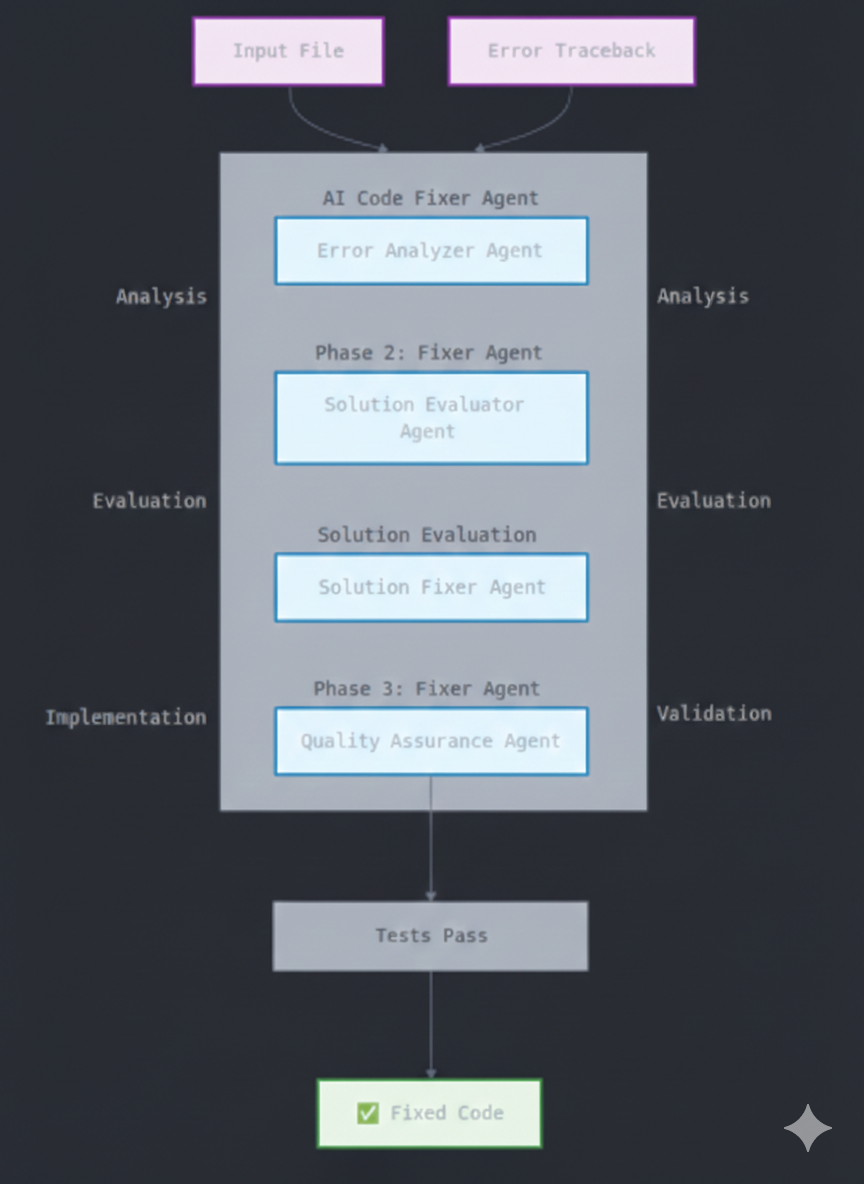
1. Analysis Phase
Before you can fix anything, you have to understand everything — and this agent never misses a clue.
Agent: Error Analyzer
Input Sources:
- Exception tracebacks from application logs
- System metrics (CPU, memory, I/O patterns)
- Historical error patterns from vector database
- Service dependency graphs
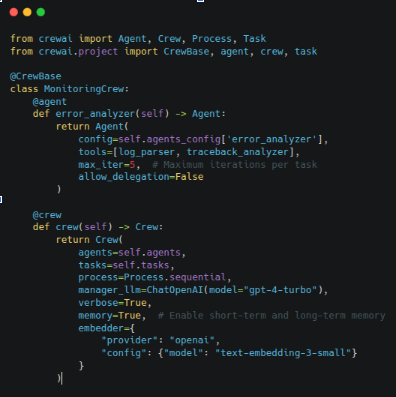
Execution Steps:
- Parses error logs using regex patterns and structured log parsing
- Extracts stack traces and identifies failing code sections
- Queries vector embeddings of similar past errors (cosine similarity > 0.85)
- Correlates error timing with system metrics to identify resource bottlenecks
- Generates 3-5 solution candidates with confidence scores
Output Format:
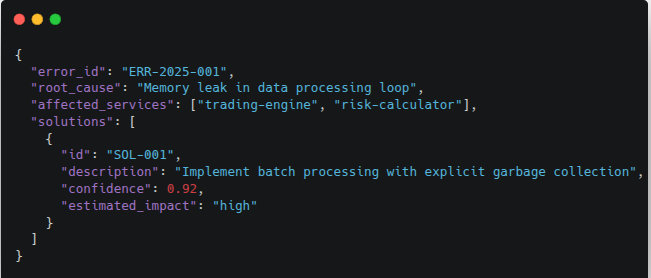
2. Evaluation Phase
Having options is easy; knowing which one won’t blow up in production is the hard part — that’s exactly what this agent lives for.
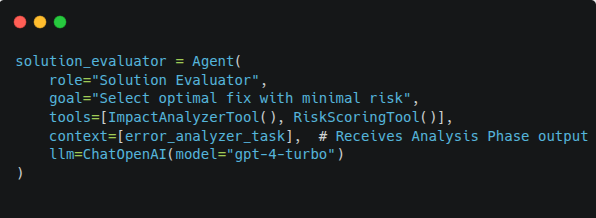
Agent: Solution Evaluator
Decision Criteria:
- Code complexity delta (lines changed, cyclomatic complexity)
- Historical success rate of similar fixes
- Regression risk assessment
- Deployment window compatibility
Technical Process:
Scoring Algorithm:
Final_Score = (Success_Rate * 0.4) +
(Impact_Score * 0.3) +
(Feasibility * 0.2) +
(Time_to_Deploy * 0.1)
3. Implementation Phase
Talk is over — this agent rolls up its sleeves, opens the codebase, and makes the change with the precision of a surgeon and the discipline of a senior engineer.
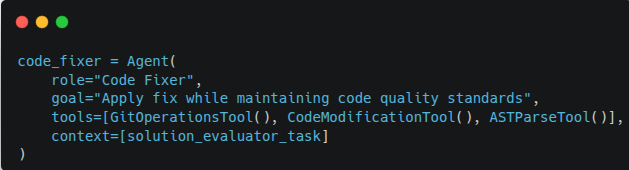
Agent: Code Fixer
Safety Mechanisms:
- Creates feature branch from main branch
- Generates git commit with detailed description
- Preserves original code in backup branch
- Implements changes with inline comments explaining modifications
Technical Process:
Implementation Phase execution-flow:
- AST Parsing: Parses code into Abstract Syntax Tree
- Targeted Modification: Modifies only affected nodes
- Code Formatting: Runs black/prettier for consistency
- Linting: Validates against pylint/eslint rules
- Documentation: Updates docstrings and comments
Code Change Example:
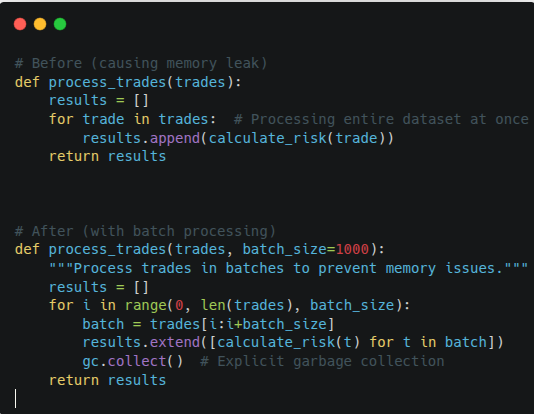
What it solved –
This code change replaces a memory-intensive, linear process with a batch-processing strategy to ensure system stability during high-volume trading. By breaking down large datasets into manageable chunks and incorporating explicit garbage collection, the updated function prevents the “Before” version’s tendency to crash under load. This directly addresses the scalability bottleneck mentioned in your problem statement, moving from a fragile, spreadsheet-style logic to a robust, production-ready implementation that preserves memory and prevents operational downtime.
4. Testing Phase
Nothing ships until this agent says so — and it doesn’t say so until every test passes, every metric holds, and every edge case is accounted for.
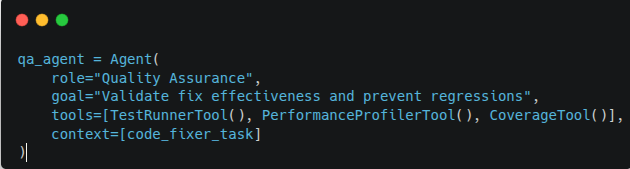
Agent: QA Agent
Test Coverage:
- Unit tests for modified functions
- Integration tests across affected services
- Performance regression tests (latency, throughput)
- Edge case validation
Technical Process:
Validation Criteria:
- All existing tests must pass
- New tests for the specific bug must pass
- Performance metrics within acceptable range (±5%)
- No new vulnerabilities introduced (SonarQube scan)
How We Implemented CrewAI
Assigning clear roles to these agents ensures task decomposition, streamlined collaboration, and separation of concerns — a core benefit of CrewAI’s role-based design.
- Configured Agent Tools & Capabilities
Each agent was equipped with specific tooling and interfaces to interact with our system:
- Logging and observability APIs for gathering errors and telemetry
- Source repository access for code modifications
- Assembled Agents into a Crew
We assembled these agents into a Crew within CrewAI, defining a workflow where outputs from one agent become inputs for the next. CrewAI’s orchestration logic ensures agents run in the correct order and can communicate via shared context, making the pipeline resilient and modular.
- Event-Driven Flows & Conditional Logic
Using CrewAI’s flow control features, we defined event-triggered transitions and conditional checks so that:
- Anomaly detection events (errors, alerts) kick off the pipeline
- Agents trigger next steps only after verifying outputs and conditions
- Failures in one phase can be re-evaluated or escalated automatically
This provides structured automation without hard-coding sequential logic outside the framework.
- Logging, Observability & Feedback
All agent actions, decisions, and outputs are logged and aggregated to support audit trails, dashboards, and continuous improvement. This allows us to:
- Track how each agent arrived at a decision
- Measure success rates and performance of fixes
- Refine solution ranking and detection criteria over time
Summary
By integrating AgenticAI (CrewAI) into our stack, we transformed monitoring & operations from manual / threshold-based scripts to a smart, adaptive, multi-agent automation pipeline. This gives us:
- Real-time, proactive detection of issues — often before they become critical.
- Faster root-cause analysis across services / layers.
- Automatic or semi-automatic remediation or alerting, reducing manual toil.
- Transparent, auditable workflows and decision trails.
- Modular, scalable architecture — easier to extend and maintain.
In short: we built an autonomous operations backbone that dramatically improves reliability, reduces manual burden, and scales with the system.
